
Distributed Systems
Let’s dive into the challenges that we will face when designing and developing an Event-Driven System and talk about the notable characteristics of a distributed system.
Overview
Although distributed systems introduces a fair amount of complexity, they deliver enormous benefits such as scalability, fault-tolerance and availability.
We can make the system scalable when every service is stateless and takes on specific responsibilities. Other properties such as fault-tolerance and availability comes along after a specific understanding of the system.
Identifying point of failures
The first task when designing a distributed system is identifying the essential services that needs to keep working to guarantee the correct functionality of the system. When doing this we enable fault-tolerance, as the entire system can only continue to operate when all critical services are up and running.
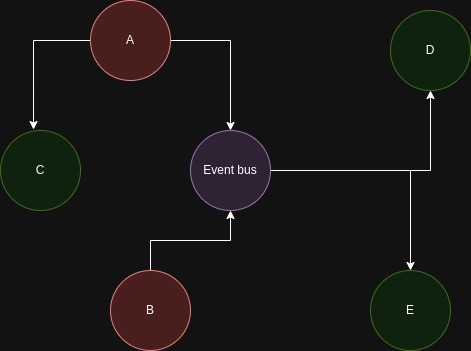
As figure 1 demonstrates out identification of the both services A and B as critical services and needs to keep running no matter what, so those services are gonna get special treatment. We could then assume that the services in Green could be coped with when they go down although we should assess the situation in every scenario including the event bus.
When making the services A and B stateless we can make them easily fault-tolerant by spinning at least one instance of each service. If they are state-full we would have to reconsider if this needs to be the case.
To scale a service that writes to the database, we need to use a mechanism that guarantees idempotency and consistency by coordinating the operations via transactions for example. read more about ACID.
Sometimes it’s not possible to entirely get rid of the state from the application. If it needs to live somewhere we could use redis if speed is crucial of a transactional database if consistency matters. Also we should add more resources to the application in this case (vertical scalability).
Consensus protocol
It should be noted that consensus protocols can address fault tolerance in stateful services. Particularly when dealing with state machines, they can be transitioned into a distributed framework using consensus algorithms like Paxos and Raft, two of the most renowned.
Consistency vs availability
The CAP theorem includes Consistency, Availability and Partition Tolerance. In a distributed system we need Partition Tolerance because the systems are not immune to network failures that’s why we have to choose between Consistency (CP) and availability (AP). Even when choosing AP, we still need to choose a consistency model that regulates how the data is viewed and updates across nodes.
Generally, a system will work under normal conditions therefore we would have to choose between latency and consistency, as the PACELC theorem states.
Consistency: eventual vs strong
Eventual consistency is a guarantee that when an update is made to a distributed data storage, the data will be eventually updated and consistent across all nodes when querying the data. The point of using eventually consistent databases is to achieve high availability. an example of this would be a “like” feature, the user may not see the current number of likes immediately but eventually the number would be consistent.
Strong Consistency means that the data would be returned in it’s latest state but due to strong consistency implementation, the delay or latency would be higher.
Event-driven applications usually prefer Eventual over strong consistency but it’s possible to use both models in the application.
Idempotence
Idempotence is crucial when developing Event-driven systems with eventual consistency model. The process could be interrupted and would need to re-do an operation, we would need to make sure that the repeated operation is performed only once, especially when working with at-least-once delivery guarantees.
Distributed transactions
In a database system, an atomic transaction is a series of operations performed on a database such either all occur (COMMIT) or nothing occurs (ROLLBACK). In a concurrent programming system, the atomic transactions are defined as linearizability. Most relational databases support atomic operations, making them a good fit for distributed systems, however sometimes we need atomicity in a NoSQL databases that do not support transactions.
Change Data Capture
CDC stands for Change Data Capture, is a process of identifying the changes made to the data in the database and delivering those changes in real-time to downstream systems. This topic got more popularity in the streaming systems over the years and for good reasons. It solves the problem of “atomically” writing to multiple stores.
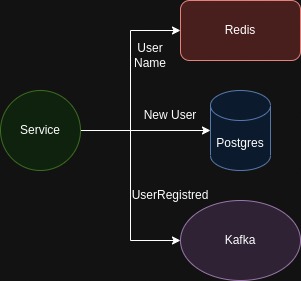
Suppose a service that after creating a user successfully, it needs to write the user name to redis, save the new user into the database and send a new event to the messaging system, announcing this new change. it’s virtually impossible to guarantee the atomicity of these operations, maybe we could implement idempotency or a roll-back mechanism, e.g. using saga pattern but the complexity will increase significantly with those implementations.
CDC enables linearizability by reading the transactional log of the database, like in the following figure:
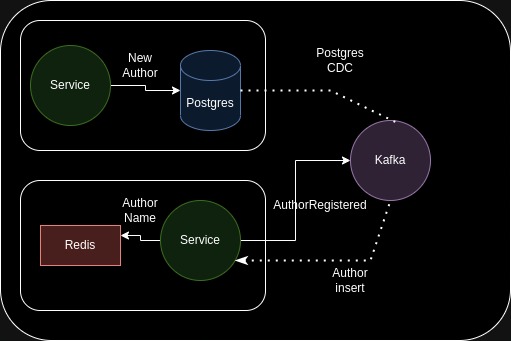
Outbox Pattern
Another CDC pattern is the popular outbox pattern. It enables strong consistency and by relying on the transactions on the database. However it will make the database a bottleneck which is something we need to avoid in streaming and event-driven systems, something we have to consider.
Distributed Locks
A Distributed Lock Manager (DLM) is crucial for coordinating access to common resources in distributed systems. It’s commonly used in operating systems, cluster managers, and distributed databases.
Using Redis, you can create an effective, lightweight distributed lock that’s inherently safe, free from deadlocks, and fault-resistant.
The concept is straightforward when working with a single Redis instance. A client can secure a lock by generating a key with a defined expiration time, commonly known as time-to-live or TTL.
For instance,SET my_lock client_uuid NX PX 30000
This means: If the my_lock key does not already exist (NX), set it with the value client_uuid and an expiration of 30000 milliseconds (PX). If the key is present, another client has the lock, and you’ll need to try again after a brief pause.